Over the summer of 2017, I was fortunate enough to land a Data Science internship at the Center of Applied Data Science (Malaysia). My colleagues were incredibly patient and supportive throughout my time there.
During my time there, I was introduced to Natural Language Processing, where textual data could be machine readable, and understandable. This was mind-blowing! Language, one of the attributes that make human, human - could be understood by machines; This thought astounded me.
Which brings me to the topic of Topic Modelling, a branch in Natural Language Processing where instances of text are treated as documents and each document are assumed to have a mixture of topics. This method of Natural Language processing teases out the hidden topics from documents using the probability of recurring words within a topic.
So like any Data-driven project, we need data to begin with. What better source than Twitter? Filled with Topics, overflowing with Text. Initially, my plan was to get a Twitter API and train my Topic Model on tweets that are from individuals of interest. However my Twitter Developer application was only approved after a year. So I decided to train the model on MY own tweets instead. Mind you, I was only active on Twitter whilst I was in High School, so its safe to say that my tweets were nothing short of embarassing.
Cleaning the data was not easy. Because tweets would normally contain links, symbols, and/or emojis, this took quite a while. For example, each tweet would look something like this:
'RT @9GAG: No one likes this pie :(\nhttps://t.co/onvV5sqOYU https://t.co/zJq34Xy1ft'
def strip_links(text):
link_regex = re.compile('((https?):((//)|(\\\\))+([\w\d:#@%/;$()~_?\+-=\\\.&](#!)?)*)', re.DOTALL)
links = re.findall(link_regex, text)
for link in links:
text = text.replace(link[0], ', ')
return textAbove is an example function that I used to remove all the links with the use of regex.
def strip_emojis(text):
"""
Remove emojis and other symbols
"""
emoji = re.compile("["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
"]+", flags=re.UNICODE)
text = emoji.sub(r'', text)
return textI also had to remove all the emojis from my tweets - as a 13 year-old girl discovering an outlet to freely express herself, I had alot. There were other functions that removed numbers, stop words, and symbols, which can all be found on my github repo.
After text cleaning, I applied NLTK’s wordnet lemmatizer to convert the word back to its “original” form. So for example the word “playing” would turn to “play”, and “singing” would turn to “sing”. This should not be confused by its counter part - Stemming. Which basically takes a word and chops the end of it. So “confused” would just become “confus”.
To understand the data better, I plotted my Twitter activity over time to predict the kind of topics we’d be getting.
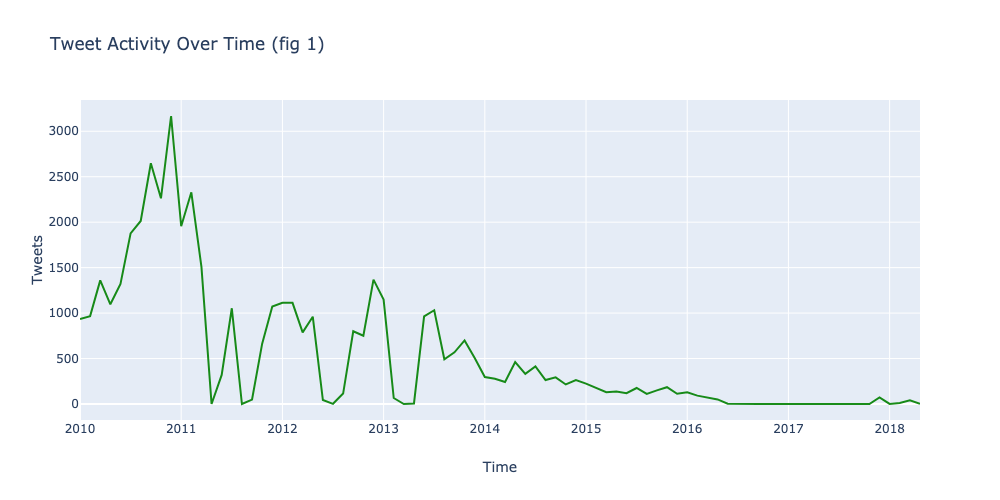
My activity was the highest September of 2010, and gradually decreased till now.
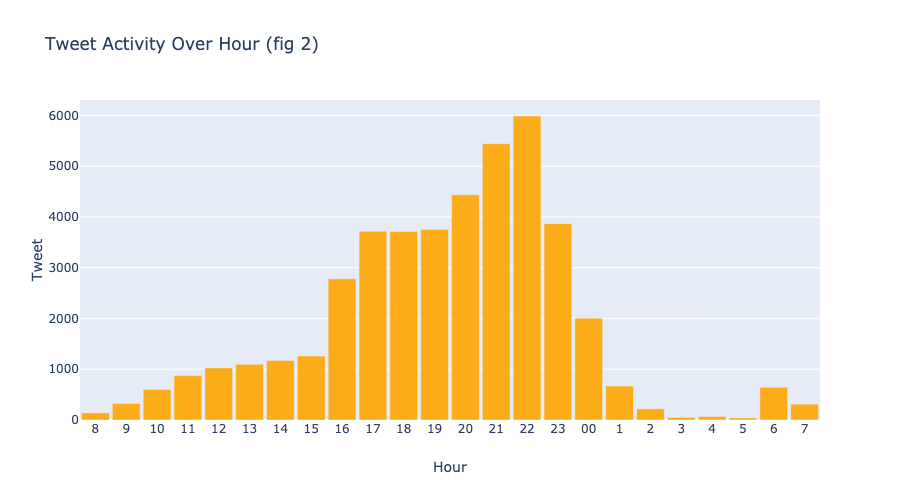
I also found that 14% of my tweets were tweeted 10pm at night.
As for Topic Modelling, I created a dictionary of my data and converted it into bag-of-words. I then applied the term frequency - inverse document frequency (TF-IDF) to evaluate the importance of each word in a topic.
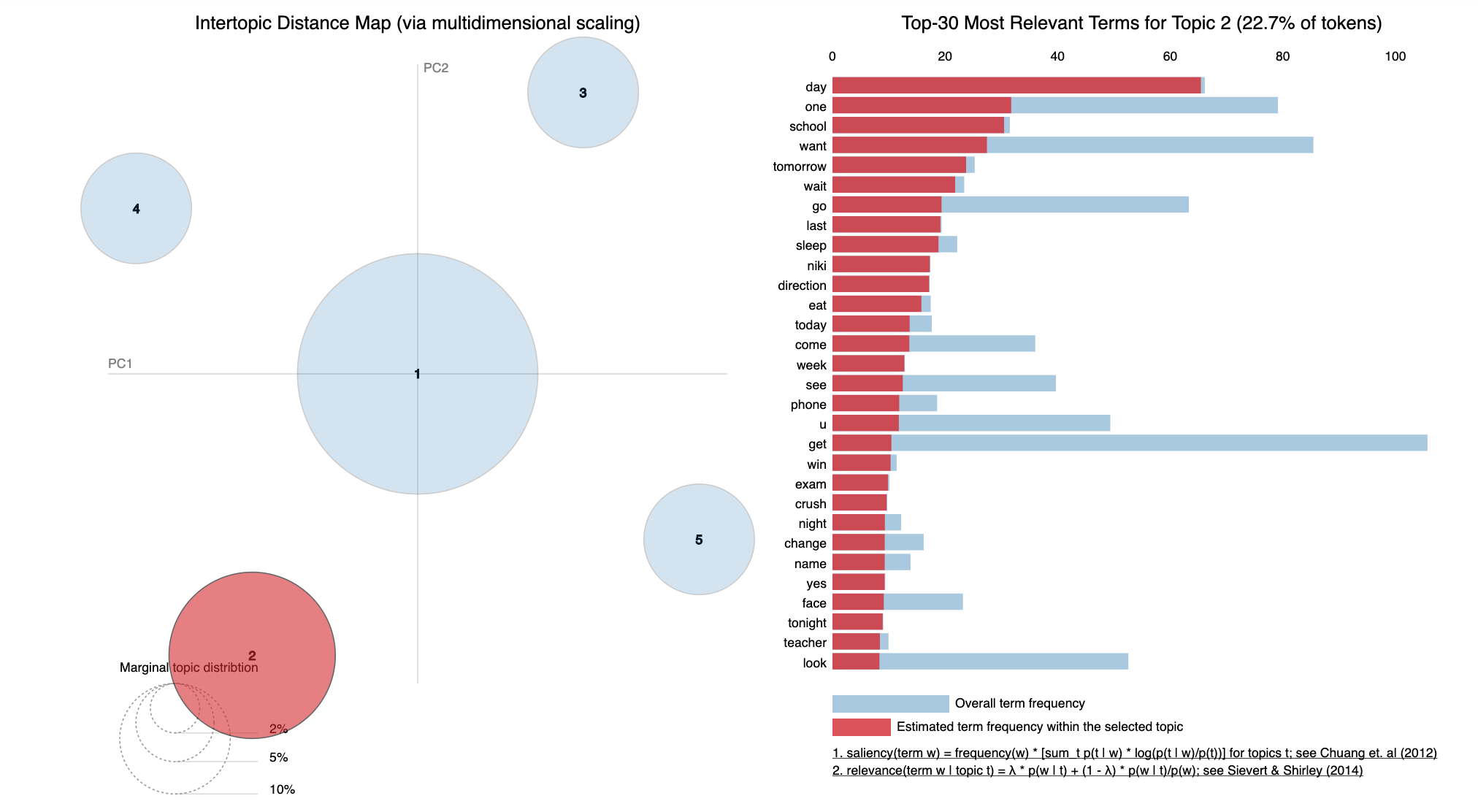
When the model is generated, it should come out looking like this. pyLDAvis is a great python package for the visualisation of topic models. The blue bars represent the overall frequency of a word in the entire corpus (collection of documents), while the red bars represent the frequency of a word in the topic. The circles are the identified topics, the largest circle being the most frequent topic to appear in the entire corpus. In this case, topic 2, which appears in 22% of the entire corpus is quite revolved around school, and exams. The other smaller topics were about One Direction and the words of admiration that I used to use to describe them. (lol!)
In conclusion, this project was a great opportunity for me to get a taste of preprocessing, manipulating, and applying models to data. It has opened my eyes to the world of Data, and its boundless application opportunities. I’ve only scratched the tip of the iceberg over the course of this project, and am eager to learn more. Happy coding!